Nobody is happy when operational data issues result in poor analytic-based decision making, much less your customers
Learn about 7 critical pitfalls to avoid while working with your data and the latest innovations from Zectonal to help discover them through our innovative data observability monitoring software
From the citizen data scientist to the world’s largest data enterprises, most organizations are not properly equipped to adequately monitor the very asset that has become a critical dependency for their algorithms and business insights – Data. Due to the sheer volume of data, it is not practical for humans to find data quality issues leading to faulty outcomes. Rather, a blazingly fast and scalable software approach is required.
Imagine the CEO of a publicly traded Fortune 500 firm making forward leaning earnings statements with incomplete and late quarterly Point-of-Sale (“PoS”) data
Imagine an algorithmic financial trader making hundreds of trades per minute based on delayed market input data, only to discover later a broken data feed that resulted in larger-than-expected financial losses
Imagine a doctor making a diagnosis using a machine learning model trained on duplicative data that biases inference predictions, leading to incorrect diagnosis
These scenarios are examples where operational data issues impact decision making. More often than not faulty data pipelines or poor data content largely go unnoticed. Lack of confidence in data and insight apathy can often set in and stall an organization’s momentum towards using data for better business decisions. Lead the way in your organization towards cleaner, better data by establishing a comprehensive Data Observability and Data Quality initiative and avoid these seven pitfalls that can derail your efforts.
Reason #1 – Your Data Stopped Unexpectedly and Nobody Noticed
Data Extract-Transform-Load (“ETL”) routines and data pipelines often produce operational outages. If you’re like most programmers or work with one, you’ve probably heard the phrase “don’t close that lid!” at one time or another as a lengthy python script ran its course on a laptop. Operational data flows and transformations can stop for many reasons but knowing when something or someone interrupts your data flow and creation is a fundamental rule for effective Data Observability monitoring.
CIO magazine recommends implementing service-level agreements (SLA’s) with every technology vendor. These agreements define “the level of service you expect, laying out the metrics by which service is measured, as well as remedies or penalties should agreed-on service levels not be achieved.”
Whether expecting data every second, every day, or once a month – with Zectonal you are able to negotiate and monitor appropriate SLA’s between you and your data provider. Let’s say your data is late. Zectonal can help you monitor your data against agreed upon SLA’s with your data vendor. This ability to monitor your data allows you in turn to tie financial incentives as well as penalties to these SLA’s, ensuring your data arrives and flows in a timely manner.
In the screenshot below, data expected on an hourly basis is late by almost 15 hours! A keen observer will also notice that this is not the first time this data pipeline has missed data this week.
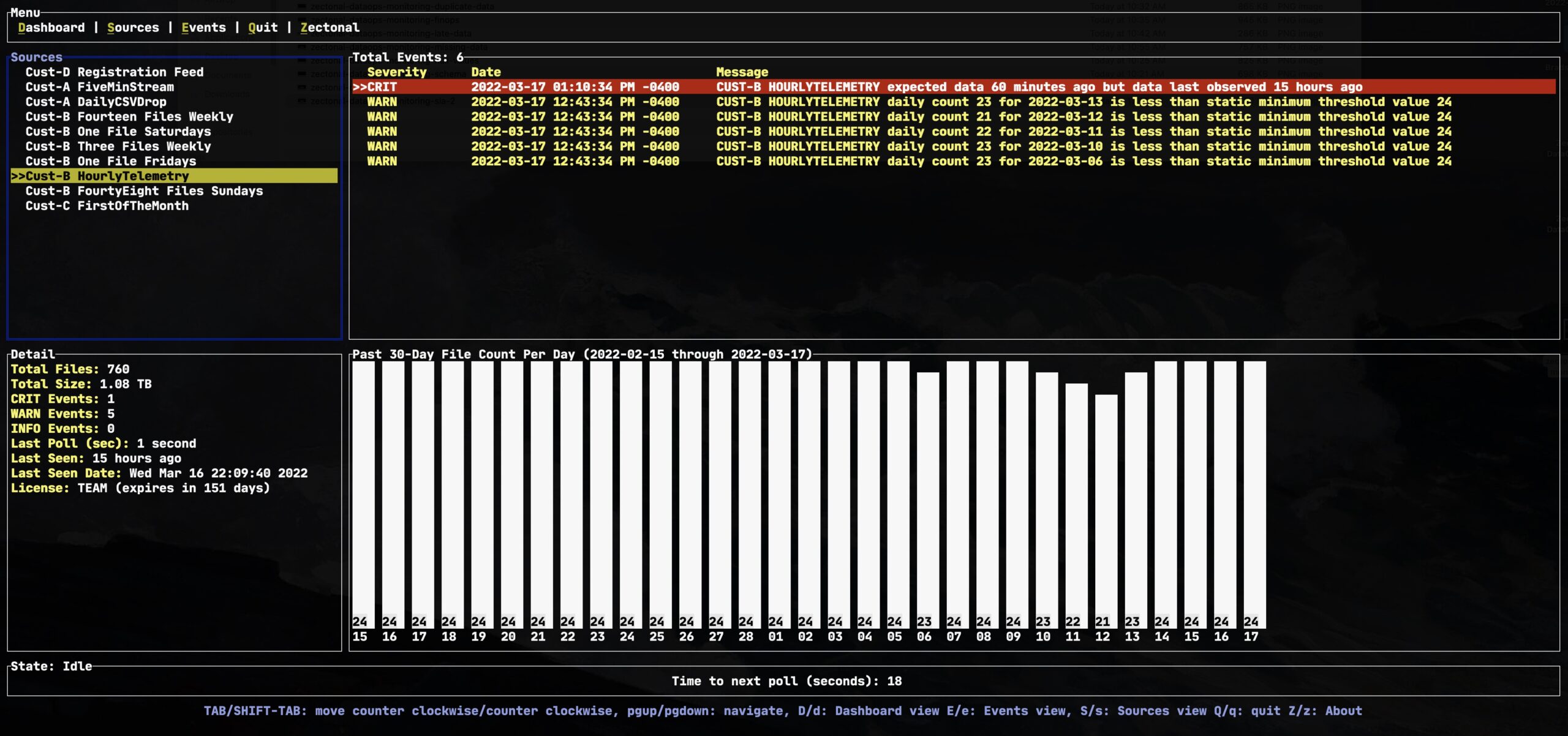
Reason #2 – Your Data Volume is Deficient
A common use case for monitoring data volume is the number of files delivered per day. Often, data pipelines and the batch ETL processes are consistent in the number of files that are produced on an hourly, daily, or even monthly basis. Monitoring the file counts over these time windows is an easy and simple way to determine the health of your flows. Knowing if a specific number of files are missing over a measured time period is an easy way to determine if the entire volume of expected data has been received. Receiving a lower number of expected files is a clear indication of a problem somewhere upstream in the data supply chain. Receiving a significantly higher number of expected files is often an indication of duplicate data.
According to a Cornell University Computer Science Research Paper, “…a data stream has necessarily a temporal dimension, and the underlying process that generates the data stream can change over time. The quantification and detection of such change is one of the fundamental challenges in data stream settings.”
https://www.cse.psu.edu/~duk17/papers/change.pdf
In the example below, this data pipeline delivers a file every 5 minutes. We can see using our software that there 2 occurrences in the past 30 days (February 23rd and February 24th) where we received a single extra file each day. We can see an occurrence on February 22nd where we received 2 less files that what we expected. Depending on the sensitivity of the consistency of the delivery of this data, an analysis that relies on this data might want to be validated for the 3 days in question.
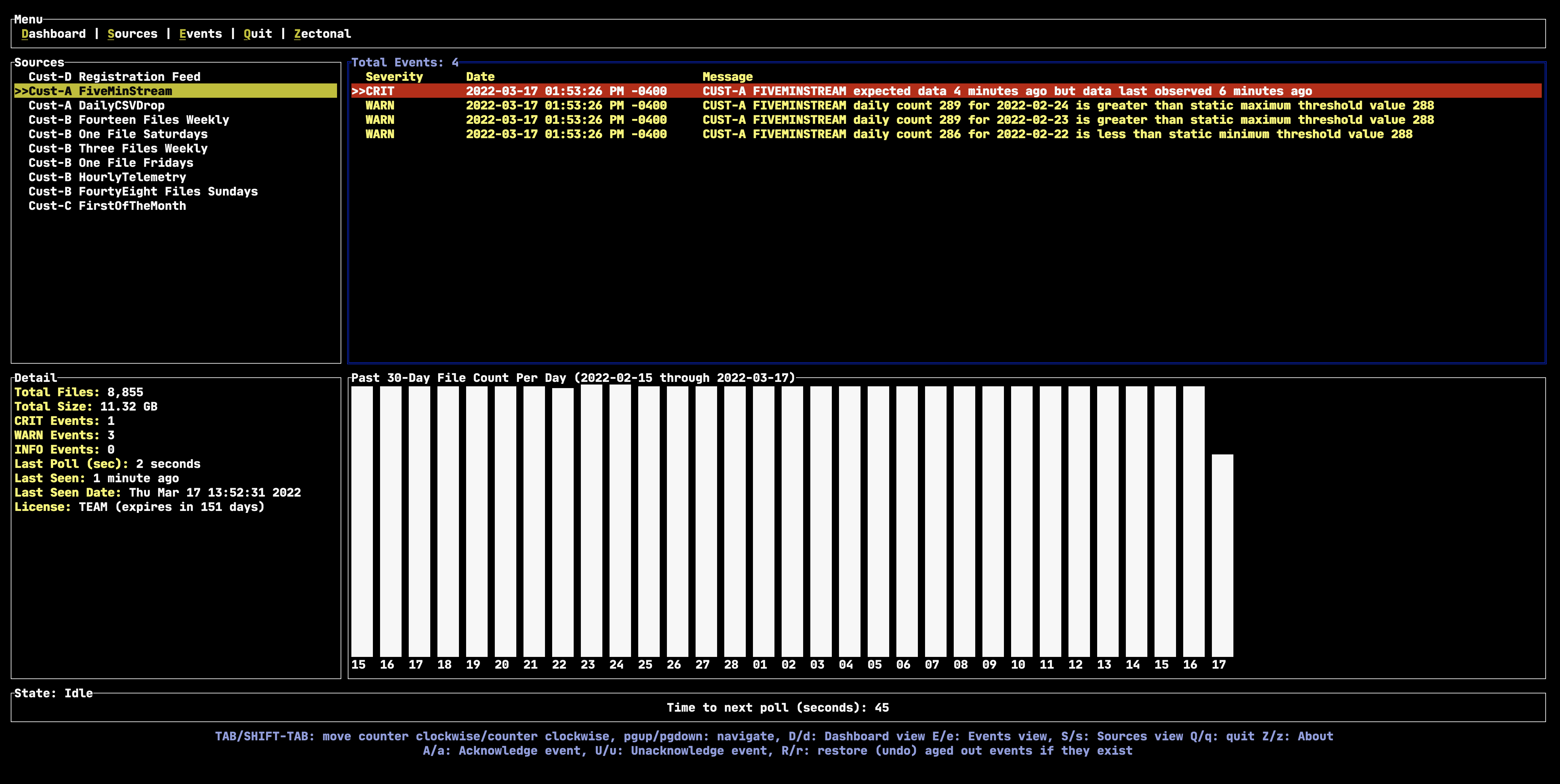
Another approach to monitoring volume is based on aggregate file sizes using a time-windowed approach. Using aggregate sizes (usually measured in bytes) can be tricky but only monitoring file counts may not always be sufficient for determining the correct expected data volume. Zectonal monitors both the number of expected files as well as aggregate file sizes and expected bytes over a specified time period. Of course it is normal for data volumes to fluctuate over time, and so measuring data volumes using static, fixed thresholds may not always be the most realistic way to determine if the data you are expecting is what you are receiving. Zectonal uses additional statistical methods to determine the appropriate rate of change, and alert users when these dynamic thresholds occur.
Reason #3 – Your Data Is Unknowingly Corrupted
Data that is structured and has a defined schema should be monitored for compliance. One of the most common root causes for operational issues involving big data is receiving data with a slightly different schema than originally expected. For columnar data formats such as spreadsheets and CSV files, this might include an extra unexpected column due to formatting errors.
Doesn’t it make sense to try to identify changes to expected data schemas earlier than later? An important consideration and differentiator for our approach to data quality monitoring is to detect quality defects as early in the data transformation process as possible. For example, Zectonal’s software could be useful to identify non-escaped comma’s within the content of CSV files. Schemas within the data supply chain change over time, and those changes are often not communicated in advance, leading to downstream analytical production issues. Zectonal can remedy this by alerting users when it observes a corrupted schema.
In the screenshot below, we can observe that the Zectonal software detected where a single row is corrupted inside a CSV file, alerting the user with a critical event.
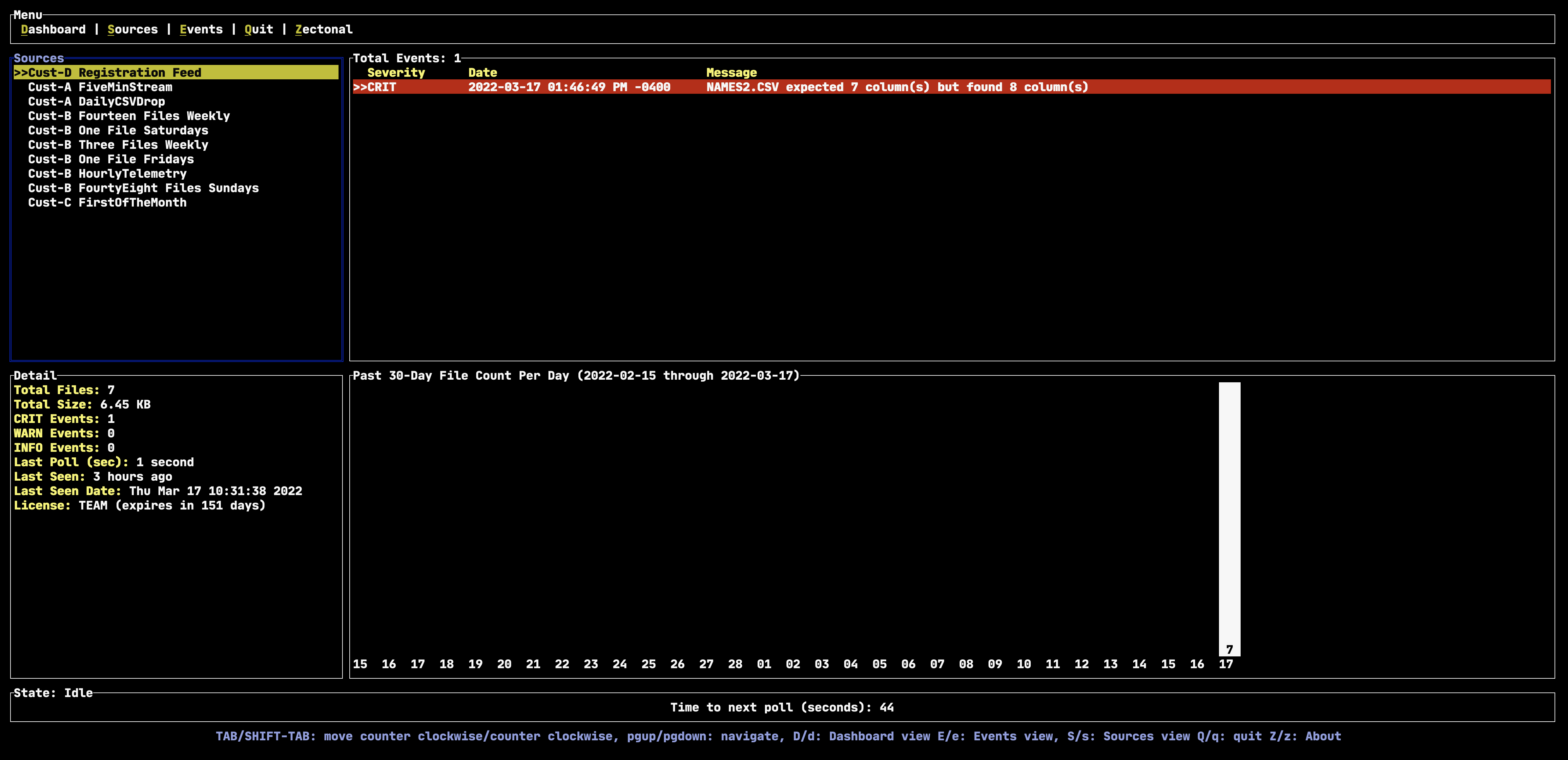
The alternative to not knowing when schemas change can result in very subtle and yet flawed analytics. Imagine a CSV file containing a structured set of financial numbers that suddenly start including un-escaped commas within the dollar amounts, leading to unexpected parsing errors. Maybe an upstream financial software system was upgraded, and the new software includes comma’s for readability but the prior version did not. The best-case scenario is that an analysis of this financial data breaks. The worst case is that dollar amounts are parsed incorrectly, do not break the analysis, and result in erroneous results. The even worse case is that the erroneous results are subtle enough to go unnoticed for a long period of time. Zectonal can identify malformed data quickly, saving companies time and money.
Reason #4 – Unfortunately, Your Data May Be Incomplete
Data is often densely packed and transported into industry-recognized file formats like CSV/TSV, JSON, Apache Parquet, Apache Avro, etc. These files can contain millions of rows and hundreds of columns allowing for billions of “data points” per file.
Within such densely packed data, it is not uncommon for many of the values to be empty or contain Null values. Machine learning often refers to these as sparsely populated datasets, or sparsely populated features. Imagine receiving hundreds of these files per day containing billions of data points each – it is beyond a human’s capacity to observe and detect anomalies in data sets at this scale. In the case of machine learning training, a significant percentage change in the sparsity of the training data can result in significant changes to the trained model, which in turn can lead to drastically different analytical outcomes and predictions.
But what if you could detect how many Null or empty values you should expect in these very dense files? This is a more difficult problem, and one that Zectonal excels (no pun intended). With Zectonal, our software monitors Null value thresholds to allow users to establish a known baseline of Null values to monitor against.
In the example below, we set a threshold to alert us if the total Null value in CSV, TSV, or Parquet files exceeds 5% of the total data content. We can see that these files all contain Null values that range between 11-12% of the total number of cells within each of the files.
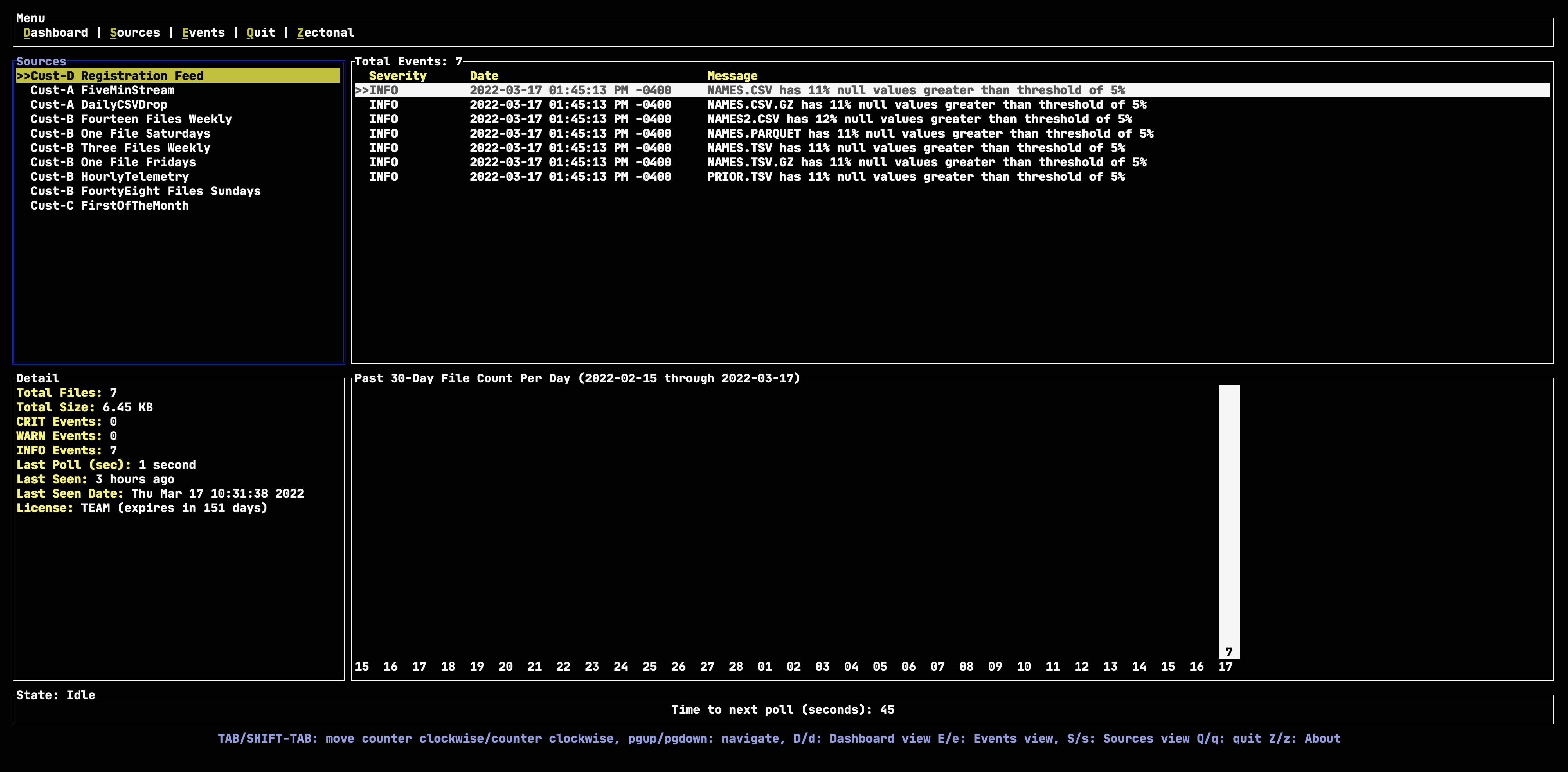
Reason #5 – Your Data Is Duplicative And You’re Still Storing It
Duplicative data is not only expensive but can lead to biased outcomes when used for analysis or machine learning training initiatives. Some industries price datasets based on volume of data, so it can be in their best interest to make data they sell larger than the content it contains.
A study by Experian found that as many as 94% of organizations suspect that their customer and prospect data may be inaccurate. According to experts, duplication rates between 10%–30% are not uncommon for companies without data quality initiatives in place. Those duplicate records can affect a company in a variety of ways and result in measurable costs.
Knowing if your data is duplicative can cut business costs dramatically no matter what industry you are in. Managers do not want to waste time and money sending duplicate marketing materials to sales prospects or contacts much less look unprofessional with multiple points of contact with one customer.
The Data Warehouse Institute estimates that this type of data duplication costs U.S. businesses more than $600 billion annually.
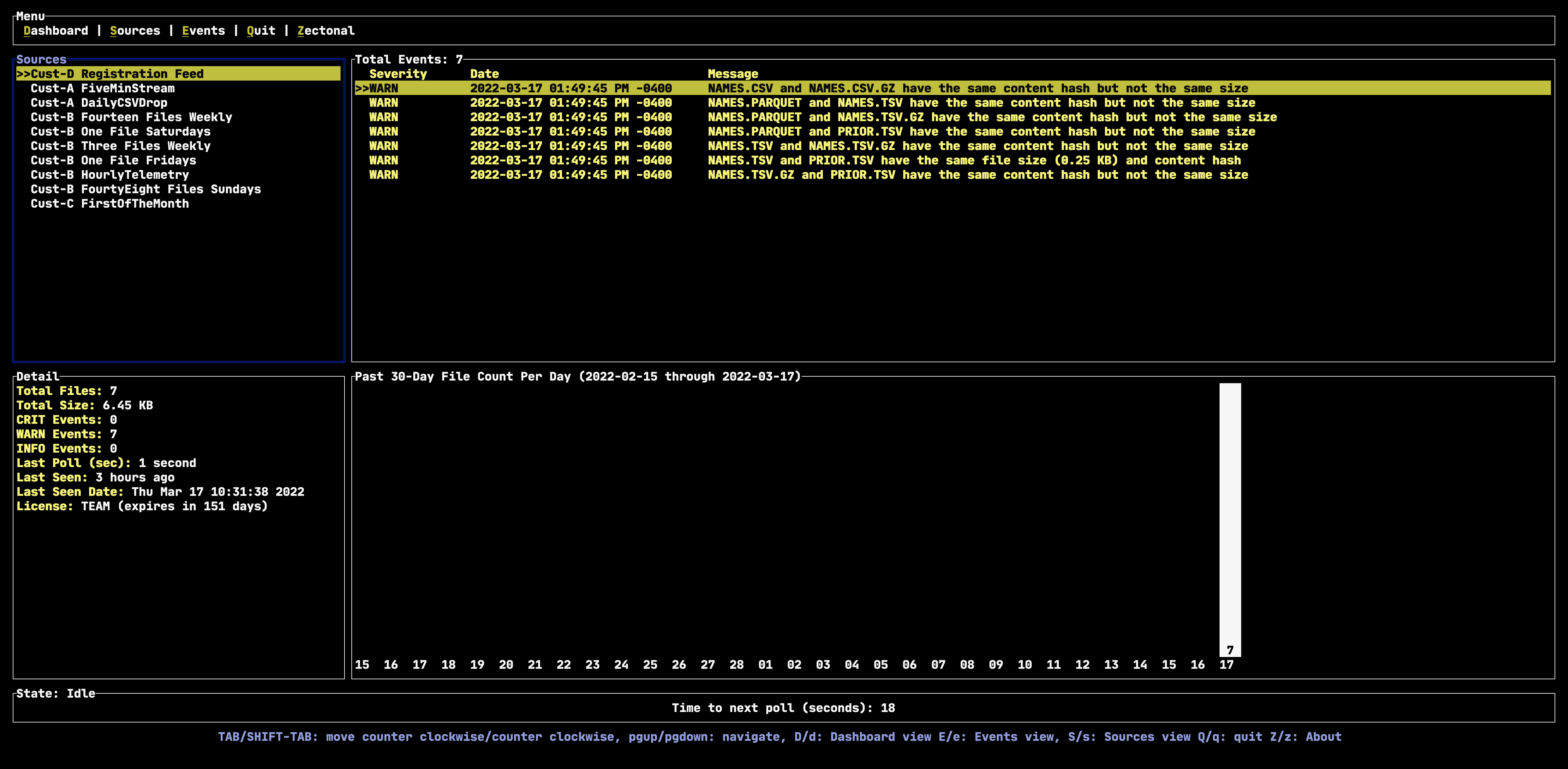
File checksums are a common way to determine if two files are the same and is an indicator Zectonal uses to determine duplicative data. Zectonal goes one step further, and when supported, analyzes the content of the data to check for duplicate data. This allows us to detect duplicate content in uncompressed and non-compressed files, or in different file formats (CSV files that contain the same data except in a TSV format).
In the screenshot below, we can easily see that the same data content is being “repackaged” in multiple file types and compression schemes. Only in one single case are the checksums equal to detect duplicate files. Zectonal can see through this and alert you when you have both the same checksums and content, giving you the enhanced awareness of whether to store duplicate data.
Reason #6 – When It Comes To Your Data, Better Late Than Never Is Not Okay
When using time-sensitive data it is often necessary to determine if the data you are receiving is late. Measuring late data is different than measuring data that has stopped – an important differentiation.
Late data presents a conundrum for end-users since you may have conducted transformations, aggregations, and analysis already in the absence of the late data.
Should end-users “redo” all of the transformations that occurred not knowing that the data was incomplete? For on-going training of machine learning models, late data could result in the need to retrain models in order to more accurately generalize real-world conditions. This is unrealistic and time consuming and avoidable.
Or you could just tell your upstream data provider to send their data on time because you have Zectonal watching them!
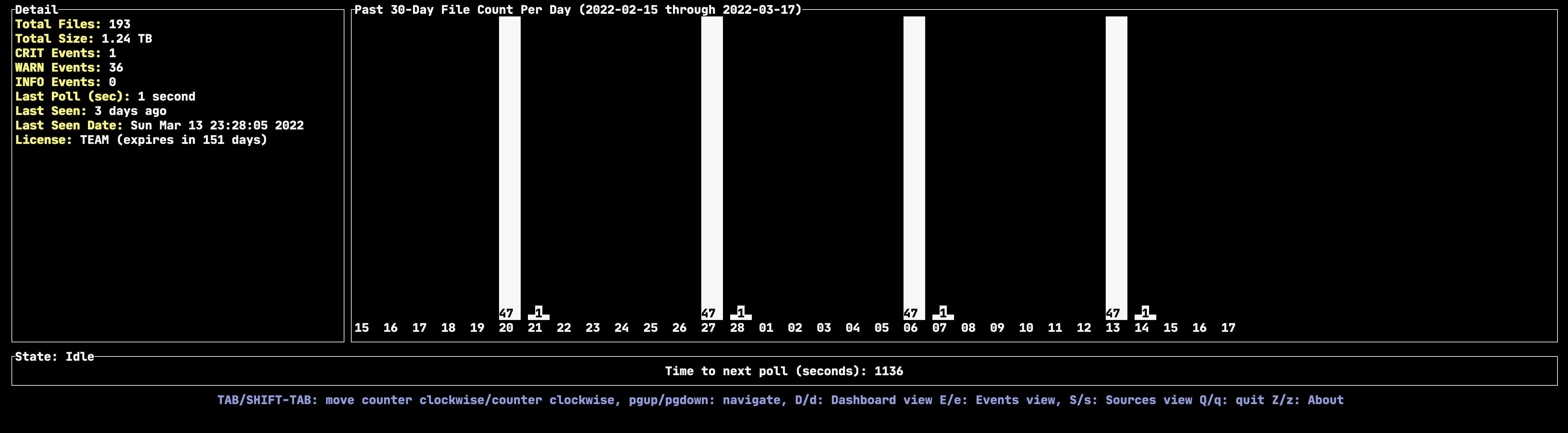
Zectonal’s proprietary analysis help identify late data in your data sources. In the screenshot below, we can observe that a single file is late for delivery, consistently every week (arriving on Monday morning versus with the other 47 files each Sunday). This type of analysis can ensure that no training or re-training of machine learning models occurs before receiving the late data each week.
Reason #7 – Data Is Expensive Already, And You Are Likely Paying More Than You Should
Many organizations, especially in the FinTech and AdTech industries, are increasingly purchasing third party data sets, or alternative data, as a way to gain market advantage over their closest competitors.
“The global alternative data market is expected to grow from $1.70 billion in 2020 to $2.41 billion in 2021 at a compound annual growth rate (CAGR) of 41.4%.” Source: Reportlinker.com’s, “Alternative Data Global Market Report 2021: COVID-19 Implications And Growth.”
Gaining a holistic view of your alternative data sets can help ensure your ability to take full advantage of such a large investment. Zectonal’s ability to monitor your data SLA’s while identifying missing, malformed, incomplete or duplicative files saves you money and minimizes additional data expense while ensuring you get your money’s worth.
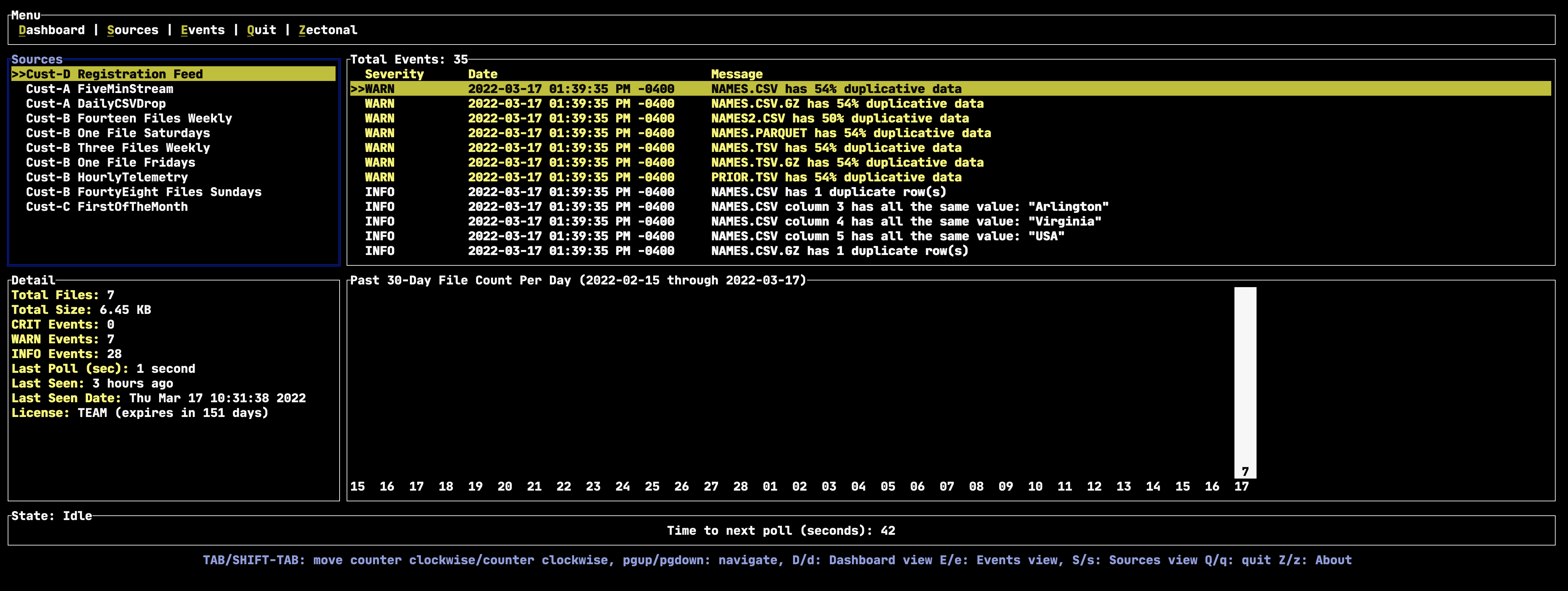
In the screenshot below, out software summarizes for each file how much duplicative and Null value data is present. With the particular data source, multiple files have more than 50% of its content as duplicative – this does not include Null values. Although not in the screenshot, we take it one step further and assign a financial cost to this duplicate data at its source making it easy to understand the financial impact of duplicative data.
Zectonal is the first to develop unparalleled software capabilities to ensure a complete and blazingly fast situational-awareness of your data. Feel more confident in your data. Generate impactful insights. Make better business decisions with less hassle, and at a faster pace.
Join The Conversation at Zectonal for additional Data Observability and AI Security topics in the future, including Data Supply Chain Threat Detection and Data Security.
Know your data with Zectonal. https://www.zectonal.com
About the Author: Dave Hirko is the Founder and CEO of Zectonal. Dave previously worked at Amazon Web Services (AWS), Gartner, and was a Founder and PCM Member of the top-level Apache Metron Big Data Cybersecurity Platform that was implemented by Fortune 500 institutions to find cyber anomalies using Big Data analytics.
Feel free to reach out to Dave at dave@zectonal.com