In our previous article Don’t Underestimate the Importance of Characterizing Your Data Supply Chain we described how data supply chains operate globally, and how they are vulnerable to disruption through operational neglect and emerging AI Security attacks.
In this article, we demonstrate and describe how a single intentionally formatted text string inside a densely packed big data file (e.g., malicious payload) containing millions of other valid data points was used to trigger a Remote Code Execution (“RCE”) exploit. This action was possible via a no-code Extract Transform Load (“ETL”) process associated with ingesting data into a data lake or data warehouse.
Our intent with publishing our research is to describe a new type of generic attack vector that uses common big data file types to transport a malicious payload deep inside an enterprise’s network and data analytics software infrastructure. The ultimate target of this attack vector is an organization’s data lake and/or data warehouse, and subsequently the intentional manipulation of the AI and analytic systems that consume that data.
One objective of such an attack, and that is described in this article and is based on our real-world demonstration, is to take remote control of software systems deep inside an enterprises’ network.
Another objective of this attack, and that is not explicitly demonstrated in this article, is to deliver counterfeit/fake data to a customer’s data lake and/or data warehouse so as to manipulate ML training algorithms with the intent of producing AI models that intentionally do not work as expected. This type of subversion is very difficult to detect especially if the trained AI models’ results are not egregiously different than expected, but different enough to negate the value of the ML model.
We discussed in our prior articles the techniques Zectonal has developed and incorporated into our software to detect and prevent counterfeit fake data.
We use the term big data file types to describe a general set of open source and commonly used file formats used by analytic platforms and machine learning training software. This type of attack vector, if introduced into the global data supply chain, could be used for a variety of cybersecurity attacks including, but not limited to, AI & Data Poisoning and RCE.
We believe the data flow, data processing, and cloud architectures used in our research are common and realistic. We recognize that there are many different architectures, software applications, and advanced security techniques that organizations use to achieve similar outcomes that would prohibit the specific use cases described in this article. Our objective in this article is to bring awareness to the emerging threat vectors by demonstrating a very credible and realistic attack vector.
Unique Facets of This Attack Vector
File Formats
This generalized big data attack vector is especially pernicious because, through normal operation, it circumvents many traditional mechanisms and network security tools enterprises used to detect malicious payloads. Specifically, the malicious payload itself is delivered through a data pipeline. The payload file is often in a compressed binary format that can be encrypted for additional protection. Through normal operation, the malicious payload is intentionally “protected” from discovery through the deliberate use, and combination of, binary formats, multiple types of compression techniques, and different optional forms of data encryption.
Density and Size of Data Contents
To make matters more difficult, the file structure containing the malicious payload may have millions of densely packed data points. In our demonstration, we only required a single data point within one of these extremely densely packed files to contain a specifically crafted text string to trigger the exploit and gain immediate remote code execution from within a private virtual cloud over the public Internet.
Data Flow versus Network Flow
As is common for most cloud-based architectures, the malicious data payload travels, or flows, via the data pipeline, which is itself sourced from a cloud-based storage mechanism called an object store. The data flow never transits through any type of firewall or scanning device before it is processed and ultimately gains access to a vulnerable system.
No Code Data Pipelines and ETL
In our demonstration and research there is no opportunity for intelligent coding to check the contents of the file before it is processed. We used several very common no-code data pipeline and ETL applications where all data processing instructions are provided via standard configuration files and configuration options.
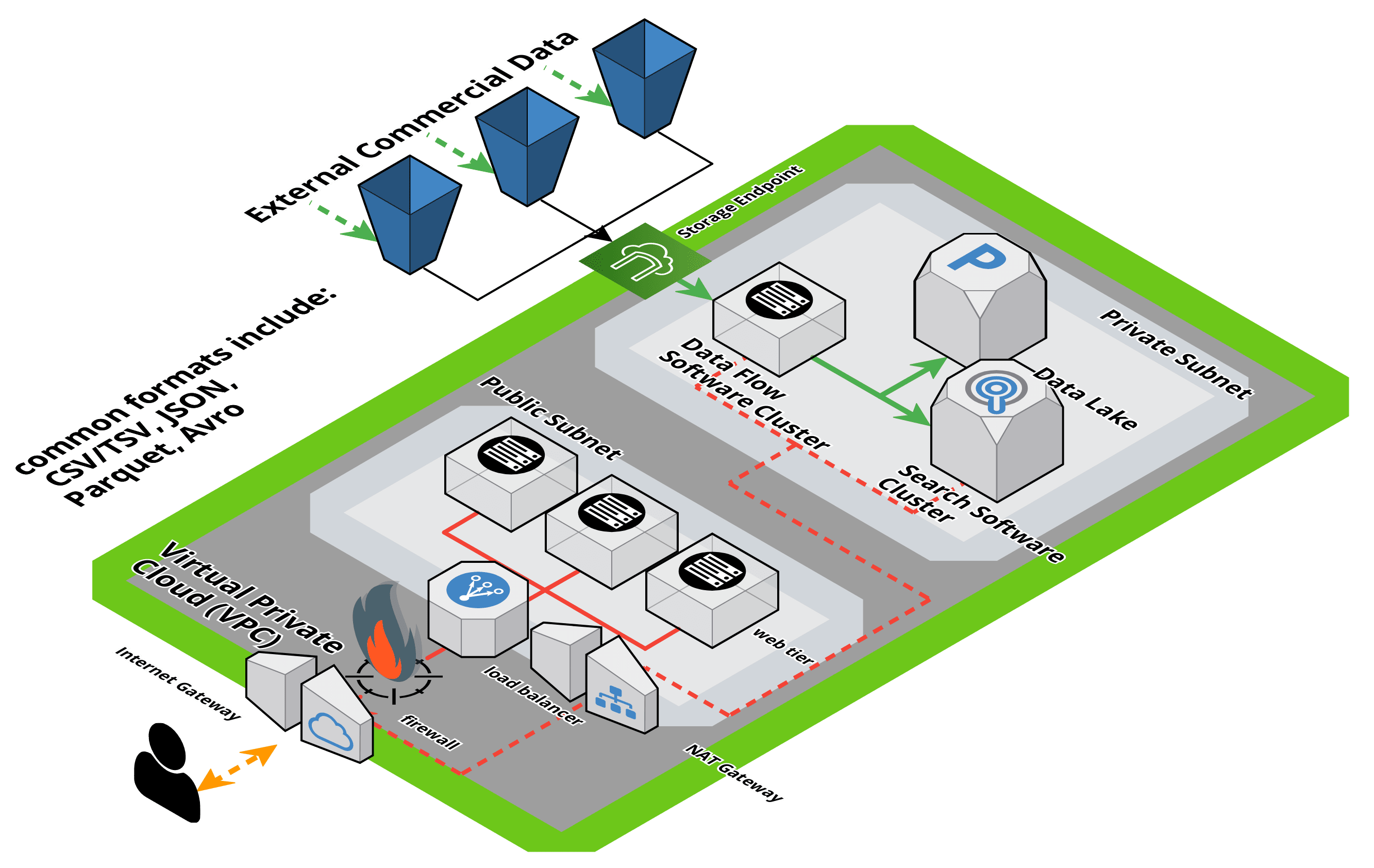
Using architectures such as the one above, and using these type of software components, we believe this type of attack vector will be leveraged in the future with many different types of exploits using many different combinations of payload packaging techniques.
Specific Data Poison Attack Using Log4j Vulnerability
Why Log4jShell?
We used the Log4jShell vulnerability and a publicly available exploit to demonstrate a specific use case of the more generic data poisoning attack vector. Although we believe the Log4jShell attack vector described in our research has not been published previously, the intent of the research is to demonstrate a real-world example of the much larger generalized attack vector, and its implications for AI Security. This specific Log4jShell attack vector, vulnerability, and RCE exploit allowed our research team to gain remote access to server(s) with private IP addresses within a private subnet inside a public cloud provider’s virtual private cloud (“VPC”). While our research used cloud infrastructure for implementing and demonstrating this attack vector, we believe that the attack vector is not limited to the cloud infrastructures and that on-premises infrastructures could be just as vulnerable depending on the security of their data pipelines.
What is Unique About This Log4jShell Attack Vector?
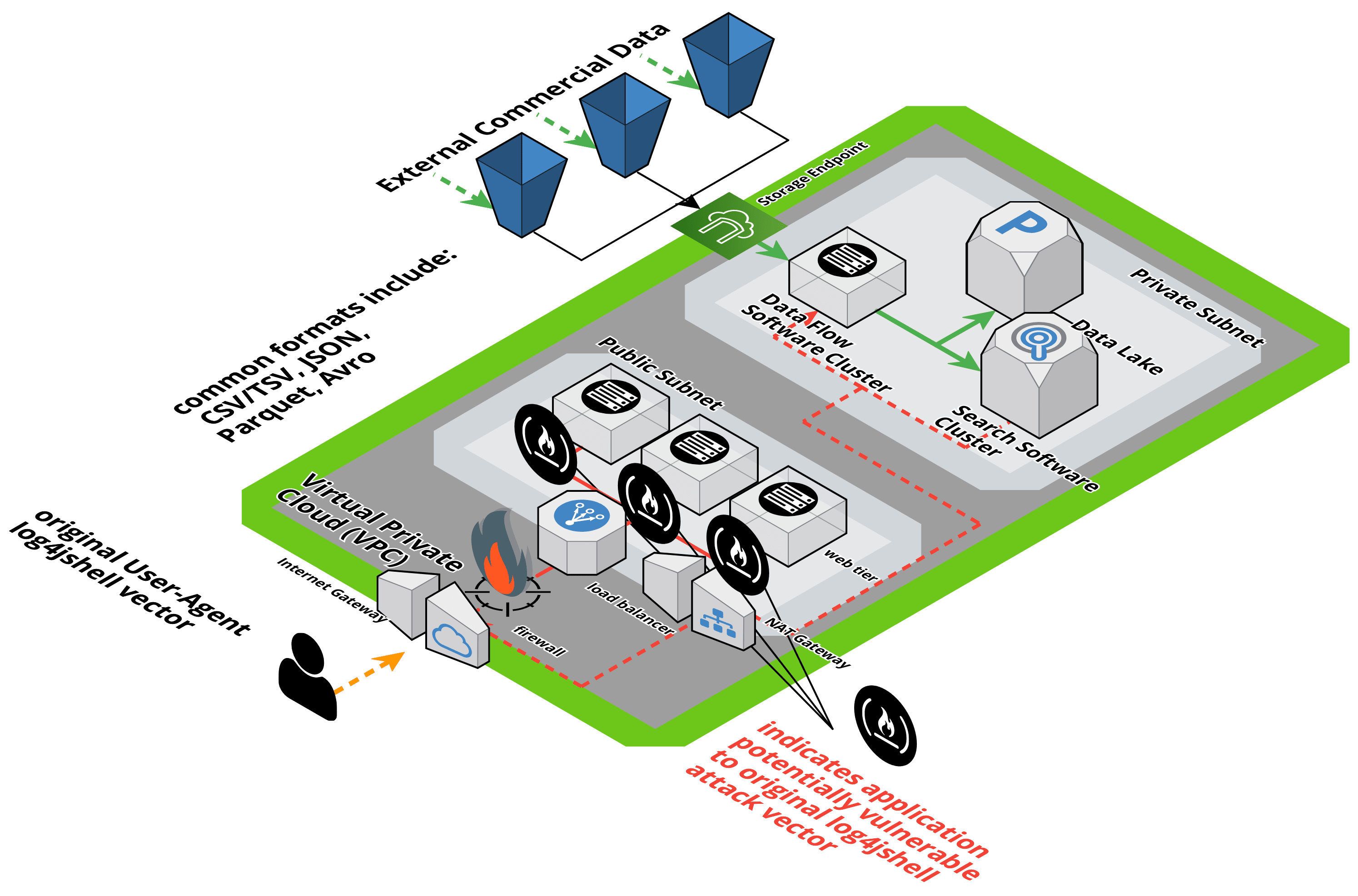
Almost all previously published reports describing the Log4jShell vulnerability and attack vector involved using a specifically crafted text-string included within the User-Agent HTTP request header to take advantage of the vulnerability and trigger the exploit.
In our research and demonstration, we used the same previously disclosed text string, but packaged it within a big data file that would be processed and subsequently triggered via an ETL process using a vulnerable software application.
Since the User-Agent string is often logged by web servers, this specifically crafted string had a high likelihood of triggering an associated exploit. This most likely assumes that the vulnerable system was accessible to the public Internet in order for an outsider to trigger and take advantage of the exploit. Assuming that was the case, anyone with an http client such as curl could configure the User-Agent and make a request to a public Internet facing system. In our experience these vulnerable publicly facing Internet web servers were often intentionally isolated as a defense-in-depth security architecture, and therefore even in the worst case scenario if they were fully compromised, the impact would be ideally limited to a single server assuming single server was adequately secured and did not provide a jumping-off point. The diagram below shows the User-Agent attack vector.
For the attack vector used in our research, the malicious payload taking advantage of the log4j2 vulnerability enters the enterprise through a different access and ingress path – namely via a data pipeline.
The data pipeline is initiated when the malicious file is uploaded to a cloud object store, sometimes referred to as a storage bucket. Many organizations download 3rd party commercial datasets available in the global data supply chain using the same file formats described herein and store them in their cloud object stores. Once the malicious file is in an object store, it is then downloaded via a no-code data flow application, which then flows the data through an ETL process and to another no-code application, ingesting that data into a data lake. The ETL process, and the vulnerable software system that processed the data, triggered the exploit which allowed an external actor to gain remote access to that server on a private subnet from the public Internet. From there the attacker could gain additional visibility to the organizations data lake and associated AI systems.
The Log4jShell embedded payload attack vector is shown in the diagram below. The data pipeline flows the contents of big data file formats such as CSV/TSV, JSON, Apache Parquet, Apache Avro, etc. to their path from outside of the enterprise to its destination in the organizations data lake. Contained in one of these files packed with millions of data points would be the specifically crafted text-string ready to take advantage of the vulnerability and trigger the RCE exploit. These pipelines and their content do not always flow through application firewalls or other content scanning devices.
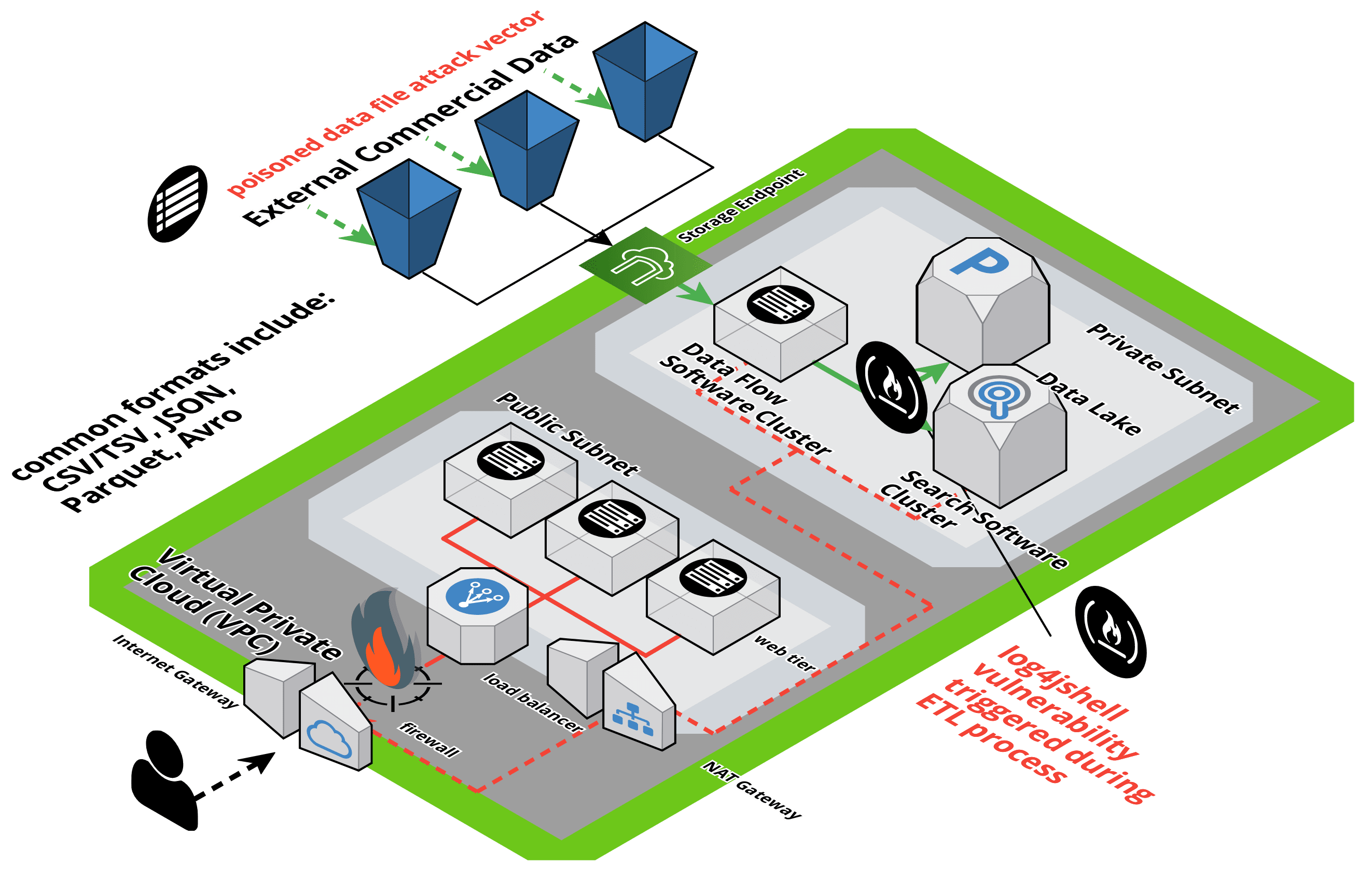
Many Big Data distributed software systems that enable data pipelines and analyze the data they provide (what we refer to within the data supply chain metaphor as the factory software machinery) are vulnerable to Log4jShell. The Department of Homeland Security (“DHS”) Cybersecurity & Infrastructure Security Agency (“CISA”) maintains a list of these systems.[1] For the systems used in our demonstration, patches specifically for the Log4jShell vulnerability were released in the days immediately following the discovery announcement in December 2021.
Comparing Log4jShell Attack Vectors
With the first attack vector (user-agent), it was extremely simple to package and take advantage of the vulnerability using a variety of http clients. The simplicity of it is what made the vulnerability so nefarious. The tradeoff being that the damage resulting from a compromise, or blast-radius, for these outer-edge web servers was fairly easy to contain, mitigate, and patch.
With the second attack vector (big data payload), creating a malicious payload within the file was straightforward, but inserting that file within the global data supply chain and ensuring it would be processed by a vulnerable system we estimate is less likely to occur. The tradeoff being that if the payload did eventually make its way to a vulnerable system, it was less likely to be identified as a threat due to the normal operating circumstances in which data pipelines, big data distributed systems, and machine learning training algorithms currently operate.
Identifying a Vulnerable System
In our research we used a very well-known distributed processing system with “millions of downloads” since its inception. We used a version of that software released several months ago in November 2021 – prior to the announcement of the Log4jShell vulnerability. In our research, we determined that approximately 2 1/2 years of software releases for this particular software component were vulnerable – the timeframe correlated directly to the inclusion and removal of the Java log4j2 vulnerable dependency. It should be noted that every aspect of the vulnerability that was exploited has an associated patch remedy that is available and would prevent this vulnerability and exploit from working.
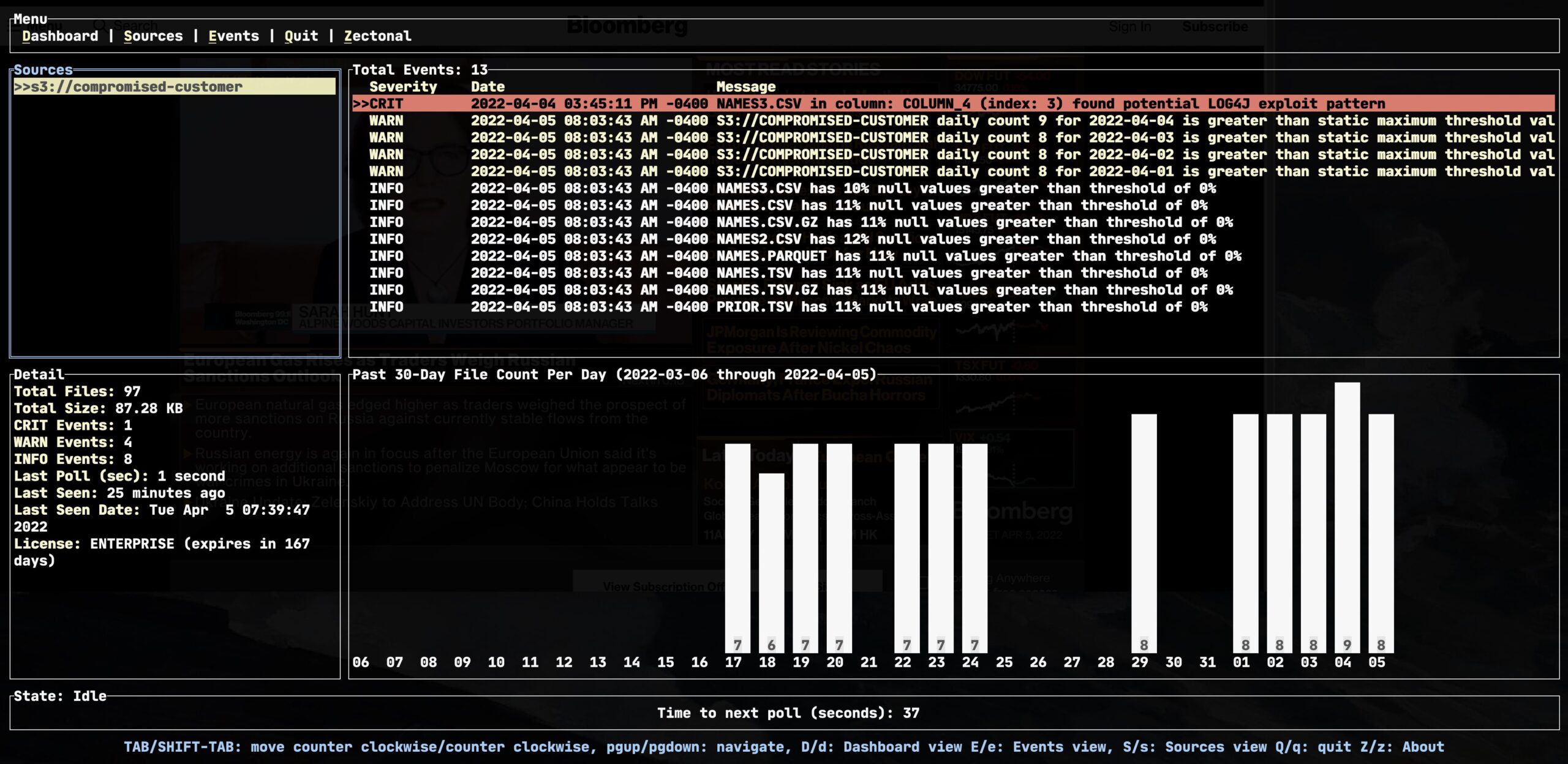
Detecting the Malicious Payload using Zectonal Deep Data Inspection™
Zectonal has implemented within its software monitoring capabilities a method for detecting these types of malicious payloads. We refer to this technique as Zectonal Deep Data Inspection™. What Deep Packet Inspection is for network security, Deep Data Inspection is for data and AI Security. In the example below, our Zect™ software application finds the specific exploit within a GZIP compressed CSV file.
Software Systems Used In Our Research
To demonstrate the specific attack and exploit, we chose to use the open source ELK stack, which is a collection of three (3) open source projects including Elasticsearch, Logstash, and Kibana.
While we were not able to determine the distribution of ELK versions deployed globally (giving us some indication of the attack surface), we did find relevant information via the Elasticsearch Wikipedia entry that it is used by Google Cloud Platform, Alibaba Cloud, and AWS. According to Logz.io which monitors log, metric, and trace analytics for any stack:
“With millions of downloads for its various components since first being introduced, the ELK Stack is the world’s most popular log management platform. In contrast, Splunk — the historical leader in the space — self-reports 15,000 customers in total.”[2]
Only the Logstash component of the stack triggered the exploit when processing a file with an embedded, specifically crafted string. At least two default configuration settings had to be changed to ensure the vulnerability was exploited and triggered by the affected Logstash application.
We used several versions of the ELK stack including version 7.15.2 released on November 10, 2021, and version 5.6.16 released on March 19, 2021. While we did not test every release in-between March 2019 and November 10, 2021 (a period of 2 ½ years), our assumption is each version would be similarly vulnerable under a specific set of environmental conditions since they all contained a vulnerable version of the Apache Log4j 2 logging library.
We intentionally chose these versions released immediately before the disclosure of the Log4jShell vulnerability on December 10, 2021, and to coincide with the use of the compromised versions of the log4j 2 libraries. We therefore believe based on these reasonable assumptions that all versions of Logstash during this 2 ½ year period would be vulnerable.
Finally, we intentionally used a specific version of Java 8 released and unpatched prior to the lo4jshell disclosure on December 10, 2021. Given that 60% of Java developers still use Java 8 in production according to the Synk JVM Ecosystem Report 2021[3], we determined this was not an unrealistic assumption for use in our research. It also provides some scope of the overall attack surface.
In Summary
A new type of generic attack vector using common big data file types to transport a malicious payload could already be inside your enterprise network or data analytics software infrastructure.
Protecting the integrity of your data is of upmost importance to ensure your analytics and AI models are not manipulated by nefarious outside influences.
Zectonal can help you protect your data lake and/or data warehouse from these types of attacks, ultimately preventing the intentional manipulation of your AI and other analytic systems that consume big data.
A real life example of a data supply chain vulnerability is the Log4jShell attack vector. Our research team gained remote access to server(s) with private IP addresses within a private subnet inside a public cloud provider’s virtual private cloud (“VPC”).
To learn more about Zectonal and how you can protect your data lake or data warehouse now and in the future, visit us at www.zectonal.com and request a free trial of our software.
Zectonal is developing unparalleled software to ensure a secure and blazingly fast Data Observability and AI Security capabilities for your data. Feel more confident in your data. Generate impactful insights. Make better business decisions with less hassle, and at a faster pace.
Join The Conversation at Zectonal for additional Data Observability, Data Supply Chain, Data Lake, and AI Security topics in the future.
Know your data with Zectonal. https://www.zectonal.com
[1] https://www.cisa.gov/uscert/apache-log4j-vulnerability-guidance